| Ročník: 2021 | Volume: 2021 |
| Číslo: 1 | Issue: 1 |
| Vyšlo: 31. ledna 2022 | Published: Jan 31th, 2022 |
| Šimandl, Václav - Dobiáš, Václav.
Analýza dat při tvorbě zakotvené teorie pomocí software atlas.ti.
Paidagogos, [Aktualizováno |
#8
Zpět na obsah / Back to content
Analýza dat při tvorbě zakotvené teorie pomocí software atlas.ti
Using atlas.ti software for data analysis through the construc-tion of grounded theory
Abstrakt: Článek se zabývá analýzou dat během tvorby zakotvené teorie podle Charmazové. Na konkrétním výzkumu jsou ukázány jednotlivé fáze analýzy dat za využití software atlas.ti a, je-li to účelné, jsou diskutovány i alternativní způsoby realizace dané fáze analýzy dat bez využití tohoto software. Nad surovými daty, kterými byly videozáznamy a do textové podoby přepsané rozhovory, bylo provedeno počáteční kódování, čímž vznikla sada kódů. Následně bylo realizováno zaměřené kódování, kdy byly počáteční kódy revidovány a z těchto revidovaných kódů byli určeni kandidáti na budoucí kategorie. Pro bližší vhled do problematiky byly mezi kandidáty na kategorie i mezi zrevidovanými kódy definovány hierarchické vztahy, čímž vznikl základ samotné teorie. Poté byla v rámci teoretického vzorkování opakovaně hledána data odporující doposud vytvořené teorii, jež po zapracování tuto teorii zpřesnila. Samotná teorie vznikla jako výstup teoretického vzorkování. Během celé analýzy dat byla tvořena mema obsahující analytické poznámky s dílčími výsledky analýzy a usnadňující navazující fáze analýzy.
Klíčová slova: Zakotvená teorie, software atlas.ti, analýza dat, kvalitativní výzkum.
Abstract: The paper looks at the analysis of data through the construction of grounded theory in ac-cordance with Charmaz. Each phase of data analysis using atlas.ti software is demonstrated by specific research and, if considered purposeful, the possibilities of carrying out a given phase of data analysis in different ways without using this software are also discussed. Raw data, consisting of video recordings and transcripts of interviews, were processed using initial coding resulting in a set of codes. This was followed by focused coding to review and refine the initial codes. The reviewed codes were subsequently used to acquire the category candidates. In order to get a deeper insight into the issue, hierarchical relationships among the category candidates and among the reviewed codes were defined, constituting the basis of the theory itself. Theoretical coding was then applied to repeatedly identify data that contradicted theory, this being processed to make the theory more precise. The theory itself arose as the outcome of the theoretical coding. Memos were written throughout the data analysis process, containing analytical notes with ongoing results (of the analysis) and facilitating the successive phase of analysis.
Keywords: Grounded theory, atlas.ti software, data analysis, qualitative research.
1. Úvod
Zakotvená teorie je jednou z velmi často používaných metod v kvalitativním výzkumu (Birks, Mills, 2011). Metodika jejího použití však není jednotná, neboť existuje několik rozdílných výzkumných designů zakotvené teorie. Čeští autoři píšící o zakotvené teorii (Šeďová, 2007a; Hendl, 2005; Miovský, 2006; Řiháček et al., 2013) se mnohdy zaměřují jen na její obecný popis a odlišnosti mezi jednotlivými výzkumnými designy zakotvené teorie v kontextu jejich filozofických východisek zůstávají často nepovšimnuté. Rozdílná filozofická východiska ale vedou u jednotlivých přístupů k využití odlišných metod výzkumu, a proto v následujícím textu porovnáme výzkumné designy zakotvené teorie z pohledu epistemologických a ontologických východisek, užité metodologie a výzkumných metod.
Autory původní zakotvené teorie jsou A. Strauss a B. Glaser. Zatímco Glaser byl zastáncem pozitivismu, Strauss byl ovlivněn především pragmatismem (Corbin, Strauss, 2008) a symbolickým interakcionismem (Oktay, 2012). Epistemologické předpoklady, logiku a systematický přístup jejich zakotvené teorie reflektují Glaserovo kvantitativní vzdělání (Charmaz, 2014). Kombinaci symbolického interakcionismu a kvalitativních metod vnesl do zakotvené teorie Strauss (Oktay, 2012).
Jelikož Strauss a Glaser vychází z rozdílných epistemologických východisek, postupem času se rozchází v názoru na kódování v rámci zakotvené teorie (Kelle, 2005) a jejich pozdější výzkumné designy se tak liší. Glaser v dalších pracích využívá pozitivistické a postpozitivistické paradigma (Mills et al., 2006). Strauss později spolupracuje s Corbinovou a společně se více přiklání k pragmatismu (Strauss, Corbin, 1998; Corbin, Strauss, 2008). Ralph et al. (2015) hodnotí jejich dílo jako pragmatický interaktivismus s konstruktivistickým záměrem. V novější práci se Corbinová podle Charmazové (2014) přiklání ke konstruktivistické pozici. Na práci Glasera a Strausse navazuje socioložka K. Charmazová, jejíž design byl ovlivněn sociálním konstruktivismem a situační analýzou (Charmaz, 2014).
1.1 Epistemologická a ontologická východiska
Filozofické předpoklady, z nichž autoři vycházejí, lze rozdělit na předpoklady ontologické a epistemologické. Podle Guby a Lincolnové (1989) se ontologické předpoklady ptají po povaze reality. Základní otázkou v této oblasti je existence objektivní reality. Epistemologická východiska zkoumají otázky, jak výzkumník dospěl ke svému poznání, konkrétně se zajímají zejména o vztah výzkumníka a zkoumané osoby a vliv výzkumníka na výsledky výzkumu. Tyto filozofické předpoklady výrazně ovlivňují zvolenou metodiku jednotlivých výzkumných designů. V Tabulce 1 jsou vypsána základní ontologická a epistemologická východiska paradigmat využívaných ve výzkumných designech zakotvené teorie.
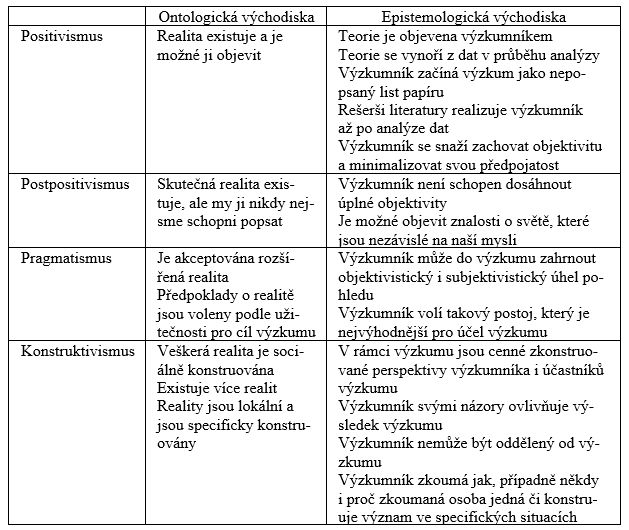
Zdroj: Oktay, 2012; Hall et al., 2013; Charmaz, 2014; Denzin, Lincoln, 2005
Autoři první generace píšící o zakotvené teorii, včetně J. Corbinové, nepsali o zakotvené teorii jako o metodologii. Pojednávali pouze o jednotlivých strategiích, technikách (metodách), které lze použít (Birks, Mills, 2011), vzhledem k čemuž neuváděli použitá epistemologická a ontologická východiska (Ralph et al., 2015). Metody používané v pracích Strausse a Glasera odkazovaly na pozitivistické resp. postpozitivistické paradigma, což však samotní autoři popírali (Hall et al., 2013).
Strauss a Corbinová (1998), resp. Corbinová a Strauss (2008) se nejvíce odkazují na pragmatismus. V novější práci Corbinová a Strauss (2008) připouští existencí více realit a zabývají se jejich povahou či konstruováním konceptů a teorií výzkumníkem. Výzkumníka umísťují přímo do zkoumané reality a data jsou podle nich konstruována společně se zkoumanou osobou, což ukazuje na jejich příklon blíže ke konstruktivistické pozici (Corbin, Strauss, 2008).
Glaserova zakotvená teorie se nejvíce podobá původní zakotvené teorii Glasera a Strausse z konce šedesátých let. Glaser ve své teorii používá pozitivistické resp. postpozitivistické paradigma (Mills et al., 2006). Charmazová se ve své metodologii odkazuje na konstruktivismus (Charmaz, 2014).
1.2 Rozdíly v metodologii jednotlivých výzkumných designů
Jelikož výzkumné metodologie jednotlivých autorů vycházejí z odlišných filozofických předpokladů a postojů (Birks, Mills, 2011), jsou mezi nimi určité rozdíly. Ty se projevují například v práci s literaturou, v přístupu k teoretické senzitivitě nebo k definování vztahů mezi kategoriemi.
Práce s literaturou. Glaserova doporučení ohledně práce s literaturou se řídí pozitivistickým resp. postpozitivistickým paradigmatem, které předpokládá existenci objektivní reality, nezávislé na mysli a vnímání výzkumníka. Glaser se obává ovlivnění mysli výzkumníka idejemi ostatních osob, a proto doporučuje, aby výzkumník začínal výzkum jako nepopsaný list papíru. V jeho pojetí by výzkumník před výzkumem ani v jeho průběhu neměl studovat žádnou literaturu týkající se zkoumané oblasti (Mills et al., 2006).
Naproti tomu Corbinová a Strauss (2008) v souladu s pragmatickým paradigmatem přistupují k literatuře volněji. Výzkumník může, ale nemusí realizovat před začátkem výzkumu rešerši literatury, týkající se daného tématu. Corbinová a Strauss (2008) vyjmenovávají možné způsoby využití literatury v průběhu výzkumu:
- Může sloužit k porovnání s výsledky výzkumu
- Může zvýšit teoretickou senzitivitu
- Může poskytnout popisná data, která v samotné literatuře nebyla příliš interpretována
- Může být zdrojem výzkumných otázek na začátku výzkumu
- Může ukázat směr, jakým by se mělo provádět teoretické vzorkování
- Může potvrdit výsledky výzkumníka, anebo naopak výsledky výzkumníka mohou sloužit k ilustraci chyb či zjednodušení v literatuře, či může vysvětlit jev, vyskytující se v literatuře.
Charmazová (2014) kritizuje Glasera pro jeho vidění výzkumníka jako nepopsaného listu papíru, tedy že by výzkumník měl studovat relevantní literaturu až po skončení výzkumu. Důvodem je, že se výzkumník podle jejího názoru nemůže oprostit od kulturních stereotypů, které má v sobě zakořeněny. Zároveň ale upozorňuje, že především v případě začínajících výzkumníků může příliš brzké studium literatury kontaminovat mysl výzkumníka cizími idejemi. Jak Charmazová (2014) dále uvádí, pokud se výzkumník dokáže vyhnout riziku kontaminace své mysli cizími idejemi, kritický přehled literatury mu dává příležitost zlepšit realizovaný výzkum.
Teoretická senzitivita. V původní práci Glasera a Strausse (1967) je teoretická senzitivita popisována jako výzkumníkova schopnost „vidět podstatná data“, což znamená zamýšlet se nad daty s pomocí teoretických pojmů (Kelle, 2005). Corbinová a Strauss (2008) definují teoretickou senzitivitu jako schopnost vybrat nuance a narážky v datech, které naznačují určitý význam nebo na něj ukazují. Je však otázkou, jak dosáhnout co nejlepší teoretické senzitivity, a proto jednotlivé výzkumné designy předkládají vlastní způsoby jejího zvyšování.
Dle Glasera je pro dosažení teoretické senzitivity důležitá výzkumníkova objektivita. Té výzkumník dosáhne, pokud bude přistupovat k výzkumu bez předchozích názorů a předsudků a dokáže rozpoznávat a zaznamenávat dění, aniž by je před tím filtroval přes své postoje a hypotézy (Glaser, 1978). Strauss a Corbinová (1998) nechtějí po výzkumníkovi, aby přistupoval k výzkumu jako nepopsaný list papíru. Místo toho přinášejí techniky zvyšování teoretické senzitivity, jejichž hlavním cílem je zbavit výzkumníka předpojatosti, domněnek, vzorců myšlení a znalostí získaných z literatury, které by výzkumníkovi mohly zabraňovat v údajích vidět to, co je důležité. Dalším cílem těchto technik je prohloubení analýzy z popisné do teoretické roviny. Charmazová ve shodě s Glaserem (1978) předpokládá, že teoretická senzitivita jde ruku v ruce s tvorbou teorie. Teoretickou senzitivitu výzkumník získává zkoumáním studovaného života z různých úhlů pohledu, porovnáváním, následováním signálů a tvorbou idejí o zkoumané skutečnosti (Charmaz, 2014).
Základní technika zachování teoretické senzitivity je stejná ve shodě všech tří výzkumných designů a spočívá v kladení si otázky: O čem jsou zkoumaná data a jaký je jejich význam? Podle Charmazové (2014) by výzkumník měl navíc hledat nejjednodušší možnou odpověď, která je ve shodě s daty.
Definice vztahů mezi kategoriemi. Glaser i Strauss a Corbinová berou v úvahu, že jakékoliv teoretické šetření potřebuje explicitní anebo implicitní teoretický rámec, který pomůže v datech identifikovat kategorie a vztahy mezi nimi (Kelle, 2005). K tomuto účelu používají Strauss a Corbinová (1998) axiální kódování, které se soustřeďuje na vytváření spojení mezi kategoriemi a jejich subkategoriemi. Dosahují toho pomocí určování podmínek kategorie, které ji zapříčiňují, kontextu, v němž je kategorie zasazena, strategií jednání a interakce a následků těchto strategií. Následně z kategorií a jejich subkategorií vytvářejí paradigmatický model. Paradigmatický model sestává ze vztahů určujících příčinné podmínky, jev, kontext, intervenující podmínky, strategie jednání a interakce a následky (Strauss, Corbin, 1998). Paradigmatický model je striktně zaměřen na popis procesu, a proto se data neprocesuálního charakteru pomocí něho těžko popisují.
Axiální kódování bylo výrazně kritizováno. Výzkumníci, kteří realizovali výzkum podle starších verzí metodologie Strausse a Corbinové, si velmi často stěžovali na komplikovanost kódovací procedury. Podle Glasera pomocí těchto metod je výzkumník nucen tvořit kategorie místo toho, aby je nechal volně vynořit z dat (Kelle, 2005). Corbinová a Strauss ve své poslední práci (2008) již axiální kódování příliš nezdůrazňují (Charmaz, 2014).
Glaser v souladu se svými pozitivistickými resp. postpozitivistickými východisky, které přepokládají existenci objektivní reality, přichází s teoretickými kódy. Tyto rodiny kódů jsou zakotveny v sociologii a popisují obecné principy fungování společnosti, které by měl výzkumník znát. Teoretické rodiny kódů slouží výzkumníkovi k vytvoření obrazu, jak mezi sebou v rámci výzkumu jednotlivé důležité kódy souvisí (Charmaz, 2014). Ve své pozdější práci Glaser popsal mnohem více teoretických rodin, přičemž sám poznamenává, že tento seznam není konečný (Birks, Mills, 2011).
Charmazová ve své konstruktivistické zakotvené teorii nevěnuje vztahům mezi kategoriemi příliš mnoho pozornosti. Vztahy mezi kategoriemi jsou konstruovány v průběhu procesu analýzy a jsou zaznamenávány do poznámek – mem (Charmaz, 2014). Ke zpřesnění vztahů mezi kategoriemi dochází až během teoretického vzorkování.
1.3 Výzkumné metody
Zakotvená teorie se obecně sestává ze sběru dat a jejich analýzy. Analýza dat má několik fází, které neprobíhají čistě lineárně, ale spíše cyklicky. Tyto fáze zahrnují kódování surových dat, tvorbu kategorií, identifikaci centrální kategorie, vytvoření vztahů mezi kategoriemi a tvorbu výsledné ucelené teorie. Jednotliví autoři výzkumných designů zakotvené teorie definují vlastní metody, které mohou mít v rámci analýzy dat rozdílné cíle.
Tyto metody tvoří v designu Glasera (2005) otevřené kódování, selektivní kódování a teoretické kódování. V designu Strausse a Corbinové (1998), resp. Corbinové a Strausse (2008) jsou těmito metodami otevřené kódování, axiální kódování a selektivní kódování. V designu Charmazové (2014) jsou těmito metodami počáteční kódování, zaměřené kódování a teoretické vzorkování. Saldaña (2013) zahrnuje otevřené kódování pod počáteční kódování; Birksová a Millsová (2011) považují tyto dva typy kódování za více méně shodné. Dle Urquhartové (2013) Glaserovo selektivní kódování odpovídá zaměřenému kódování Charmazové. Rozdíl mezi nimi je především v Glaserově zaměření selektivního kódování směrem k centrální kategorii.
1.4 Motivace a cíl práce
Jak plyne z výše uvedeného textu, jednotlivé výzkumné designy zakotvené teorie se od sebe značně liší nejen ve filosofických východiscích, ale také v metodách, které by měl výzkumník využít. Tyto metody jsou sice v rámci jednotlivých výzkumných designů přesně definovány, avšak nedávají jednoznačný a ucelený popis, jak by měl být výzkum prováděn. Mnohému výzkumníkovi tak může chybět vodítko, jak mají být uvedené metody implementovány v konkrétním výzkumu. Na druhou stranu existují manuály popisující práci s konkrétním softwarem, například (Friese, 2012). Ty však pojednávají pouze o funkcích software, nikoliv o metodě výzkumu.
Cílem následujícího textu je ukázat, jak lze design zakotvené teorie implementovat v rámci konkrétního výzkumu za použití software atlas.ti. Tímto výzkumem je v našem případě pedagogický výzkum zaměřený na digitální gramotnost žáků končících základní školu. Analýza dat je prováděna podle designu Charmazové (2014). Tento design je dle našeho názoru vhodnější než designy Glasera, resp. Strasse a Corbinové, neboť je oproti nim volnější a zároveň umožňuje pracovat s daty neprocesuálního charakteru. Na rozdíl od designu Glasera umožňuje tento design pracovat s literaturou již během výzkumu a oproti designu Strasse a Corbinové je možné se vyhnout problematické tvorbě paradigmatického modelu (Kelle, 2005). Tento design jsme zvolili také proto, že je nám z ontologického hlediska nejblíže konstruktivistická teorie, neboť se domníváme, že sociální realitu si každý konstruuje individuálně.
2. Kódování surových dat
Nad surovými daty, například do textové podoby přepsanými rozhovory a videozáznamy, je prováděna první fáze analýzy pomocí počátečního kódování. Tehdy by měly být nalezeny významové jednotky, tj. segmenty dat v analyzovaném textu nesoucí informaci ve vztahu k výzkumné otázce (Miovský, 2006). Charmazová (2014) označuje počáteční kódování jako proces zamýšlení se, o čem data vlastně jsou. Základními analytickými postupy jsou stejně jako v otevřeném kódování podle Strausse a Corbinové (1998) porovnávání a kladení otázek. Cílem tohoto procesu je identifikace kódů (Charmaz, 2014). Kódy lze chápat jako nálepky, které co nejpřesněji charakterizují jednotlivé segmenty dat. Při vytváření kódů je potřeba si klást následující otázky o povaze dat: „O čem vypovídají tato data?“, „Co tato data reprezentují?“, „Z jakého úhlu pohledu?“, „Co data tvrdí, vyslovují, nebo nechávají nevysloveno?“ (Charmaz, 2014). Je přitom možné až žádoucí, aby jeden kód byl použit pro všechny segmenty dat popisující shodný jev. Konkrétní využití tohoto principu ilustruje Ukázka 1.
Ukázka 1. V našem výzkumu jsme nahrávali obrazovku počítače, na kterém účastník výzkumu řešil zadané problémy, a prostřednictvím mikrofonu jsme nahrávali veškerou komunikaci účastníka s výzkumníkem. Během kódování jsme nalezli časové úseky, během nichž účastník zdánlivě nic nedělal (tj. ani nepracoval s myší či klávesnicí, ani nekomunikoval s výzkumníkem) a které trvaly od zlomků vteřiny po několik vteřin. V souladu s výše uvedenými otázkami jsme si u takových pomlk kladli otázku, co znamenají. Promýšlí účastník strategii, jak zadaný problém vyřešit? Prohlíží si obsah zobrazený na obrazovce? Nebo odpočívá a opravdu zadaný problém neřeší?
V software atlas.ti je možno prvotní vytvoření kódu provést pomocí funkce Open Coding a další použití existujícího kódu pomocí funkce List Coding. Alternativně lze při použití funkce Open Coding začít psát název kódu, načež atlas.ti nám nabídne seznam kódů začínajících danými písmeny. Názvy kódů by měly být dle našeho názoru převážně jednoslovné až tříslovné. Charmazová (2014) doporučuje jako kódy užívat slovesa, protože mění analýzu z popisu statického tématu na analýzu aktivního procesu. Jelikož časem může vzniknout až několik stovek kódů (v našem případě vzniklo 279 kódů), je vhodné názvy souvisejících kódů vytvářet jako navzájem si podobné a blízko sebe se vyskytující při abecedním seřazení (např. „email-používá-ano“; „email-používá-ne“; „email-vlastní-ne“). Pro rychlou orientaci při návratu k datovým zdrojům je vhodné přesně označovat co nejmenší oblasti, které obsahují kódovaný jev. Návrat k datovým zdrojům je častý zejména při dokladování výstupů analýzy pomocí citací účastníků výzkumu, jakožto techniky sloužící ke zvyšování pravdivosti výzkumu (Švaříček, 2007a).
V software atlas.ti lze kdykoliv změnit název již existujícího kódu. K tomu může dojít při využití principu konstantní komparace podle (Šeďová, 2007b). Tehdy může být zjištěno, že dva datové segmenty jsou si významově velmi podobné (např. „známky ve škole“ a „školní prospěch“), a tak by měly být označeny společným kódem a lze je tedy sloučit dohromady. Název kódu označujícího původní segment však nemusí být dostatečně obecný, aby pod něj mohl být zahrnut i nový datový segment, a tak vznikne potřeba jej přejmenovat. Při změnách názvů kódů je třeba dbát opatrnosti, aby nový název kódu stále vystihoval všechny jím označené datové segmenty.
Při některých typech výzkumů může být užito pozorování, v rámci nějž vznikají videozáznamy. Ty mohou být v souladu s doporučením Švaříčka (2007b) převedeny do textové podoby a následně ve formě textu analyzovány. Výhodou tohoto přístupu je snadná orientace v textu a s tím spojená rychlost počátečního kódování, možnost anonymizace účastníků výzkumu před započetím analýzy dat a snížení objemu dat, které musí výzkumník uchovávat. Nevýhodou je naopak možná ztráta informací při přepisu videozáznamu do textové podoby. Jestliže se výzkumník k analýze dat získaných z pozorování rozhodne přistupovat komplexně a kódovat přímo videozáznamy, software atlas.ti umožňuje i kódování takovýchto dat (viz Obrázek 1). Tento přístup jsme zvolili v rámci našeho výzkumu, jak dokumentuje Ukázka 2.

Ukázka 2. V rámci našeho výzkumu vznikla řada videozáznamů zaznamenávajících řešení zadaných problémů účastníky výzkumu. Vzhledem k obavě ze ztráty informací při přepisu videozáznamů do textové podoby jsme se rozhodli kódovat videozáznamy přímo v programu atlas.ti. Při přepisu videosouborů do textové podoby by pravděpodobně byly ztraceny některé důležité informace (např. pomlky z Ukázky 1), a tudíž by nebylo možné je využít při další analýze. Vzhledem k velkému množství informací obsažených ve videozáznamech však kódování dat v této podobě trvalo delší dobu, než kdyby byly před začátkem analýzy videozáznamy přepsány do textové podoby.
Ze zkušenosti můžeme konstatovat, že kódování videozáznamů v programu atlas.ti funguje bez zásadnějších problémů. Jedinou komplikací je časová náročnost automatické přípravy nově vložených videosouborů k dalšímu použití, během níž jsou vytvářeny náhledy z tohoto videosouboru. Tato aktivita může zabrat podle výkonu počítače a délky videa až desítky minut.
Ideje, myšlenky či hypotézy vzniklé v jakékoliv fázi analýzy dat je vhodné zaznamenávat do poznámek. Do těchto mem je možné zapisovat i poznámky týkající se konkrétních kódů (a to i přesto, že atlas.ti umožňuje zapisovat poznámky také přímo k jednotlivým kódům). Ačkoliv se tyto poznámky (např. „čtenářská gramotnost ovlivňuje práci tohoto žáka s internetem. Snaží se hlavně NEČÍST“) mohou zdát výzkumníkovi příliš popisné a banální, umožňují v pozdějších fázích výzkumu snadněji nacházet vztahy mezi kategoriemi a budovat výslednou teorii.
3. Identifikace kategorií
Po ukončení počátečního kódování je třeba provést druhou část analýzy dat, která se zabývá identifikací budoucích kategorií. Charmazová (2014) tento postup nazývá zaměřeným kódováním a jde podle ní o proces výběru nejdůležitějších kódů, které jsou kandidáty na budoucí kategorie. Tito kandidáti na kategorie jsou získáni vytříděním, vybráním, či sloučením nejvýznamnějších, anebo nejčastějších počátečních kódů.
V software atlas.ti je vhodné zaměřené kódování začít kompletní revizi všech kódů. Významově podobné kódy je potřeba sloučit (viz Ukázka 3) a některé málo významné kódy, které neodpovídají cílům výzkumu, je možno odstranit.
Ukázka 3. V průběhu výzkumu jsme se u některých žáků setkali s neznalostí některých slov (např. „lamentace“). Pro každou neznalost jednoho konkrétního slova jsme v průběhu počátečního kódování vytvořili samostatný kód (např. „nezná slovo lamentace“). Vzniklo tak několik kódů „nezná slovo...“, které jsme v průběhu zaměřeného kódování sloučili do nového kódu „neznalost slova“.
Následné vytvoření kandidátů na kategorie lze realizovat buď za použití hierarchických vztahů mezi kódy, nebo za použití Code Groups. V následujícím textu popíšeme oba přístupy.
3.1 Tvorba hierarchických vztahů mezi kódy
Tento přístup vychází z předpokladu, že mezi kódy existují hierarchické vztahy, které tvoří vztahovou síť. Některé kódy mohou být vzájemně rovnocenné, mezi jinými existuje nadřazenost, resp. podřazenost. V software atlas.ti je potřeba vytvořit novou Network a za použití funkce Add Nodes do ní vložit zrevidované kódy. Mezi těmito kódy pak lze pomocí funkce Link tvořit vztahy. Pro rovnocenné kódy lze volit vztah is associated with a pro kódy vzájemně podřazené vztah is part of. Vztahy mezi kódy lze také definovat v Code Manageru pomocí kontextového menu u konkrétního kódu. Tvorbou hierarchických vztahů se mohou zároveň kódy seskupovat. Tehdy jsou seskupovány významově podobné kódy a je hledán, či nově vytvářen kód, který v sobě abstrahuje podstatu seskupených kódů. Tím vzniká přirozený kandidát na kategorii (viz Ukázka 4 a Obrázek 2).
Ukázka 4. Uvedený přístup jsme využili v rámci našeho výzkumu, jak ukazuje Obrázek 2. Příkladem budiž kódy „pomoc od rodičů“, „pomoc od sourozenců“, „pomoc od kamarádů“ a „pomoc na Internetu“, které jsou všechny podřízené kódu „Externí zdroj informací“. Kód „Externí zdroj informací“ tedy mohl být označen za kandidáta na kategorii. Vznikla tak hierarchická struktura o dvou úrovních. Protože se pro vyhledání informací na internetu ukázala být nutnou podmínkou jistá úroveň čtenářské gramotnosti, je kandidát na kategorii Čtenářská gramotnost asociován s kódem Pomoc na internetu.
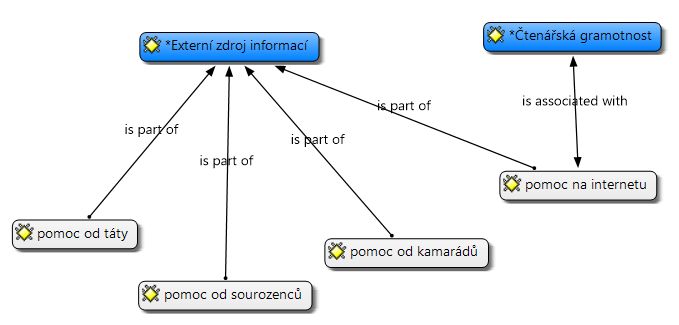
Jestliže není daný kandidát na kategorii mezi počátečními kódy přítomen, ačkoliv jsou k němu ostatní kódy zřetelně vztaženy vazbou is part of, lze jej dodatečně vytvořit 1 . Při rozhodování, zda se určitý kód má stát kandidátem na kategorii či nikoliv, lze přihlížet k počtu jím označených datových segmentů (Grounded) a počtu vazeb s ostatními kódy (Density). Tyto údaje jsou zobrazeny u jednotlivých kódů v Code Manageru. Kandidáta na kategorii je vhodné od ostatních kódů zřetelně odlišit, například změnou názvu (přidáním hvězdičky jako prefixu, aby byly tyto kódu při abecedním řazení na začátku seznamu kódů) a barevným označením.
Využití hierarchického principu může být problematické v případě velkého množství kódů, kdy nalézání vztahů mezi tolika kódy může být obtížné. Výhodou je naopak přirozená tvorba hierarchických vztahů mezi kódy a možnost kontrolovat počet vazeb mezi jednotli-vými kódy.
3.2 Využití Code Groups
Využití Code Groups vychází z předpokladu, že každý kód je významově příbuzný s dalšími kódy a že představuje součást určité rodiny kódů – kategorie. Navzájem příbuzné kódy jsou pokládány za vzájemně rovnocenné. Úkolem výzkumníka je tedy seskupovat kódy podle významové příbuznosti a odhalit tak jednotlivé rodiny kódů. Při velkém množství kódů (řádově stovky kódů) se nám osvědčilo exportovat názvy všech kódů ze software atlas.ti do sešitu MS Excel tak, aby byl každý kód v samostatné buňce tabulky. Tato tabulka se posléze vytiskne a rozstříhá na jednotlivé kódy, s nimiž je možno fyzicky manipulovat a seskupovat je podle podobnosti. Když přiřadíme všechny kódy přiřazeny do určité skupiny 2 , je potřeba tyto skupiny pojmenovat, čímž vzniknou kandidáti na kategorie. Následně je potřeba v software atlas.ti vytvořit New Code Group a pojmenovat ji názvem daného kandidáta na kategorii. Do této Code Group se přiřadí všechny kódy, které mají být v dané skupině obsaženy.
Výhodou tohoto postupu je možnost zpracovávat prakticky neomezené množství kódů a možnost filtrovat kódy podle konkrétní Code Group. To může být užitečné například při popisu kódů, které jsou zařazeny do konkrétní kategorie. Za nevýhodu lze pokládat zejména do určité míry umělé vytváření kandidátů na kategorie a potlačení vztahů mezi vzájemně rovnocennými kódy.
4. Propracování kategorií a definování vztahů mezi nimi
Po identifikaci kandidátů na kategorie je potřeba tyto kandidáty přetvořit v plnohodnotné kategorie a definovat mezi nimi vzájemné vztahy, čímž vzniká samotná teorie. Charmazová (2014) tento postup nazývá teoretickým vzorkováním a doporučuje během něho tvořit diagramy, provádět integraci mem a tzv. teoretické třídění. Teoretické třídění chápe jako vytvoření a zjemnění teoretických souvislostí, integraci kategorií do teorie a porovnávání kategorií na abstraktní úrovni. Během teoretického vzorkování by mělo průběžně docházet ke hledání dat vhodných ke zpřesnění, propracování a vylepšení kandidátů na kategorie, díky čemuž vznikají plnohodnotné kategorie (Charmazová, 2014).
4.1 Tvorba diagramů zachycujících vztahy mezi kandidáty na kategorie
V software atlas.ti je vhodné teoretické vzorkování začít vytvořením nové Network, která bude obsahovat všechny kandidáty na kategorie. Mezi nimi nyní budou tvořeny vzájemné vztahy. Během předchozí analýzy jistě výzkumník mnohokrát přemýšlel o vzájemných vztazích mezi kandidáty na kategorie, a tak nyní dojde pouze k faktickému provázání těchto kandidátů. Během této fáze analýzy se může stát, že k některým kandidátům na kategorii je nalezen jim nadřazený kandidát na kategorii 3. V takovém případě bude nadřazený kandidát označen jako kandidát na kategorii a jemu podřazení kandidáti na kategorie budou chápáni jako kandidáti na jeho subkategorie. Takovýto hierarchický systém je zcela přirozený, neboť významné kategorie obvykle mívají několik subkategorií. Další postup se liší podle toho, zda byli kandidáti na kategorie tvořeni na základě hierarchických vztahů mezi kódy jako speciální Codes, nebo jako Code Groups.
Využití Code Groups. V případě, že kandidáti na kategorie byli tvořeni jako Code Groups, v aktuální verzi software atlas.ti nelze v rámci Network mezi těmito objekty vytvářet Links. Jelikož však kandidátů na kategorie obvykle není mnoho, je možné doposud vytvořenou Network exportovat jako bitmapu a vztahy mezi kandidáty ručně dokreslit v grafickém software. Pokud je k některým kandidátům na kategorie nalezen jim nadřazený kandidát na kategorii, tento nadřazený kandidát bude v software atlas.ti vytvořen jako nová Smart Group. Jejím základem bude jeden či více operátorů OR, jejichž prostřednictvím budou vzájemně spojovány jednotlivé Code Groups, reprezentující kandidáty na subkategorie.
Výhodou použití Code Groups je jednoduchost testování vztahů mezi kandidáty na kategorie. Kromě jejich vzájemného porovnávání je možná vizuální kontrola, zda se kódy spadající pod dané dva kandidáty vyskytují v navzájem blízkých datových segmentech. K tomu je potřeba vytvořit novou Smart Group obsahující operátor OR a oba kandidáty na kategorie, jejichž vzájemný vztah je třeba testovat. Následně je možno prostřednictvím Code Manageru vybrat tuto Smart Group a aktivovat funkci Set Global Filter, čímž budou zobrazeny pouze kódy spadající pod dané dva kandidáty na kategorie.
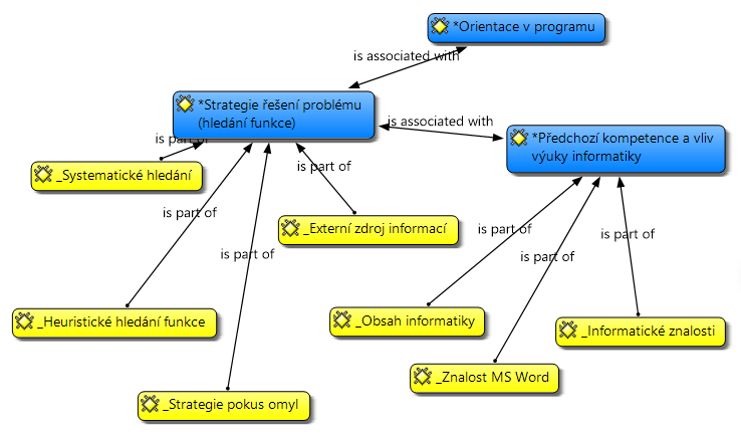
Využití hierarchických vztahů mezi kódy. V případě, že kandidáti na kategorie byli tvořeni na základě hierarchických vztahů mezi kódy jako speciální Codes, lze mezi těmito objekty vytvářet klasické Links. Mezi rovnocennými kandidáty na kategorie budou vytvářeny vztahy is associated with. Pokud je k některému kandidátu na kategorii nalezen jemu nadřazený kandidát na kategorii (jako v Ukázce 5), bude mezi nimi vytvořen vztah is part of. Kandidáta na subkategorii je vhodné zřetelně odlišit od kandidátů na kategorie, a to například změnou názvu (přidáním speciálního prefixu, aby byl tento kód při abecedním řazení umístěn mimo kandidáty na kategorie) a odlišným barevným označením (viz Obrázek 3).
Ukázka 5. Uvedený přístup jsme využili v rámci našeho výzkumu, Protože kandidátu na kategorii „Externí zdroj informací“ byl nalezen nadřazený kandidát na kategorii „Strategie řešení problémů“, byl „Externí zdroj informací“ přeznačen na kandidáta na subkategorii.
Testování vztahů mezi kandidáty na kategorie se děje zejména porovnáváním jednotlivých kandidátů na kategorie. Částečně lze využít taktéž nástrojů pro kvantitativní analýzu, jako kontingenční tabulky a korelační koeficienty. Kvantifikaci však chápeme pouze jako nástroj, který nám umožňuje lépe porovnávat souvislosti v datech. V souladu s Johnsonovou (2008) se domníváme, že při využití těchto nástrojů přistupujeme k analýze dat podle Glaserových idejí.
4.2 Integrace mem
Během dosavadní analýzy dat byla vytvořena celá řada mem, do kterých byly zaznamenávány analytické postřehy, myšlenky či výsledky dílčích analýz. Příkladem takové dílčí analýzy může být například: „V rychlosti vzdávání zadaného úkolu může hrát roli i něco jako sebevědomí při práci s počítačem. Schopnější žáci mají větší víru v sebe, tudíž jsou schopni déle hledat než žáci s nízkým sebevědomím.“ Jelikož některá mema mohou mít podobný význam, je vhodné je zrevidovat. Základem by mělo být důkladné pročtení veškerých mem. Některá duplicitní mema mohou být úplně odstraněna; významově podobná mema je vhodné sloučit podobně jako v Ukázce 6.
Ukázka 6. V průběhu výzkumu jsme vytvořili mema „orientace na internetových stránkách“ a „orientace v neznámém programu“. Protože jsou si tato mema významově velmi blízká, sloučili jsme je do jednoho mema „orientace v programu“. Přitom jsme se dopustili jisté nepřesnosti, neboť slovo „program“ v názvu mema chápeme velmi široce a zahrnujeme pod něj i internetovou stránku.
Ze zrevidovaných mem je možné vybudovat síť. To lze v software atlas.ti realizovat vytvořením nové Network, do níž budou vložena zrevidovaná mema. Mema, která na sebe významově navazují, doplňují se nebo si odporují, je potřeba propojit prostřednictvím vazeb. Takto provázaná mema se stanou základem analytického příběhu, nad nímž bude vybudována výsledná teorie.
4.3 Vytvoření a propracování teoretických souvislostí
Doposud vytvářená mema se pravděpodobně týkají pouze jednotlivých případů nebo nanejvýš počátečních kódů. Proto je potřeba je zobecnit tak, aby vypovídala o vztazích mezi kandidáty na kategorie. Obvykle je potřeba taktéž zpřesnit a lépe propracovat samotné kandidáty na kategorie, zejména je obohatit o zcela nové kódy a stávající kódy zakotvit v dalších segmentech dat (viz Ukázka 7).
Ukázka 7. V průběhu předchozí analýzy jsme vytvořili kandidáta na kategorii „vzdávání se“, který zahrnoval všechny kódy popisující moment, kdy se účastník výzkumu vzdal. V průběhu teoretického vzorkování jsme si položili otázku: „Co je příčinou vzdání se?“. Došli jsme k závěru, že příčin je vícero. Rozhodnutí vzdát se může následovat po účastníkově značném úsilí vyřešit problém, kdy po vyčerpání všech možností účastník vzdá řešení problému, protože neví, jak daný problém vyřešit. Mezi další důvody patří účastníkovo rozhodnutí problém neřešit, ke kterému dojde okamžitě po zadání problému. Možnou příčinou takového rozhodnutí může být účastníkem vnímaná přílišná náročnost úkolu, nebo jeho pohodlnost. Tyto příčiny vzdávání se chápeme jako zásadní, a proto jsme v průběhu teoretického vzorkování revidovali kódy patřící do subkategorie „vzdávání se“. Na základě této revize vznikli noví kandidáti na subkategorie. Jedním z nich je „Předčasné vzdávání se“, který zahrnuje kódy popisující situace, kdy se účastníci vzdali předčasně.
Výzkumník se v této fázi analýzy vrací zpět do surových datových zdrojů, porovnává jednotlivé případy a hledá další data podporující, nebo naopak vyvracející dosavadní představy o výsledné teorii. Toto hledání dat odporujících vznikající teorii je důležité, neboť po jejich zapracování dochází ke zpřesnění výsledné teorie. Jak uvádí Charmazová (2014), teoretické vzorkování mnohdy znamená výzkumníkův návrat zpět do terénu. Cílem je hledání případů, které by objasnily dosavadní nejasnosti obsažené v memech a umožnily saturaci dat (viz Šeďová, 2007a). Výzkumníkovi v této fázi mohou pomoci například extrémní případy (viz Ukázka 8).
Ukázka 8. Protože během dosavadního výzkumu byli účastníky výzkumu pouze žáci s průměrnými školními výsledky, realizovali jsme v průběhu teoretického vzorkování návrat do terénu. Cílem bylo za účastníky výzkumu získat extrémní případy – na jedné straně žáky s vynikajícími školními výsledky, na straně druhé žáky s podprůměrným prospěchem, kteří nezřídka mají potíže úspěšně dokončit aktuální ročník studia.
Výsledkem tohoto snažení by mělo být vylepšení jednotlivých kandidátů na kategorie, tedy obohacení o zcela nové kódy a zakotvení dosavadních kódů v dalších datových segmentech. Každého kandidáta na kategorii je potřeba porovnávat s ostatními, a je-li v konkurenci ostatních kandidátů obhájen jeho význam, lze jej prohlásit za skutečnou kategorii.
V této fázi výzkumu také může dojít k úpravě vztahů mezi některými kategoriemi, což se projeví úpravami příslušných diagramů. Dále by mělo dojít ke zobecnění mem, aby vypovídala o vztazích mezi kategoriemi. Obsah mem je potřeba testovat, zda je skutečně ukotven v datech. Mema, jejichž obsah v datech ukotven není, je nutné revidovat nebo odstranit. Zbylá mema budou obsahovat výpovědi, které pravděpodobně nebudou zcela triviální a mohou mít například formu sady předpokladů a z nich vyplývajících závěrů. Pokud některá kategorie obsahuje několik subkategorií, budou se některé výpovědi týkat pouze jedné subkategorie. Takto zobecněná a navzájem provázaná mema tvoří analytický příběh, který představuje kostru hledané teorie. Ukázka 9 zachycuje kostru námi vytvářené teorie, která se zabývá učením se ovládání neznámého programu. Pro lepší porozumění jsme také vytvořili celkové schéma této teorie, které je zobrazeno na Obrázku 4. 4
Ukázka 9. „Protože funkce určené k řešení problémů jsou v daném software integrovány, strategie řešení problémů se povětšinou týkají výběru optimální funkce, která daný problém vyřeší, a jejího vhodného použití. Strategie, které žák použije, volí v závislosti na svých předchozích znalostech a zkušenostech z podobných situací, zejména s podobným software. Na efektivitu použitých strategií dohlížejí žákovy metakognitivní kontrolní mechanismy. Na základě dosažených výsledků u žáka může (ale nemusí) docházet k učení, které zlepšuje žákovy znalosti a dovednosti, a tím ovlivňuje způsoby řešení podobných problémů v budoucnu.“
Na základě analytického příběhu a kódů obsažených v jednotlivých kategoriích je vytvářena závěrečná zpráva o vybudované teorii. Vhodnou metodou může být volné psaní, kdy je volně a kreativně zapisováno vše, co výzkumníka k dané kategorii či vazbě mezi kategoriemi napadne. Tento text je následně revidován do kapitol a dokladován citacemi účastníků výzkumu nebo popisem konkrétních situací zaznamenaných během pozorování. Takto vytvořená závěrečná zpráva může mít mnoho stran, což dokládá i případ námi vytvořené teorie, která byla publikována jakožto součást disertační práce (Dobiáš, 2019, s. 83-91).

4.4 Nalezení centrální kategorie
V předešlém textu jsme upozadili nalezení centrální kategorie modulu. Charmazová totiž oproti designům Glasera a Strausse a Corbinové význam centrální kategorie potlačuje na úkor širšího popisu, jak jednotlivé kategorie a jejich subkategorie společně tvoří abstraktní zakotvenou teorii (Birks, Mills, 2011). Centrální kategorii obvykle není nutně explicitně hledat, protože se v průběhu analýzy vynořuje samovolně z dat. Zpravidla je touto kategorií kategorie, která je velmi dobře ukotvena v datech, je s řadou dalších kategorií provázána prostřednictvím vztahů a vypovídají o ní mnohá mema. V našem výzkumu jsme za centrální kategorii zvolili kategorii „Strategie řešení problémů“, neboť se nám pro vytvořenou teorii jeví jako klíčová.
5. Závěr
Zakotvená teorie je kvalitativní výzkumná metoda určená k odhalování souvislostí v datech a tvorbě teorie. Ačkoliv je tato metoda poměrně hojně využívána, nepodařilo se nám nalézt zdroje popisující, jak metody zakotvené teorie implementovat v rámci konkrétního výzkumu za použití specializovaného software. Na konkrétním výzkumu byly proto ukázány jednotlivé fáze analýzy dat podle designu Charmazové za využití software atlas.ti.
Přínos námi realizovaného článku lze spatřovat v tom, že výzkumníkovi poskytuje vodítko, jak lze prostřednictvím software atlas.ti poměrně efektivně realizovat pedagogický výzkum založený na zakotvené teorii. Za limit námi popsaného přístupu lze považovat nedostatečné reflektování technik určených ke zvyšování spolehlivosti a důvěryhodnosti v rámci kvalitativního výzkumu, které by spočívaly ve spolupráci více výzkumníků (jde například o dvojité kódování či reflexi kolegů). Aby bylo možno tyto techniky používat opravdu efektivně, byla by potřeba spolupráce výzkumníků pracujících na různých zařízeních v reálném čase. K tomu by bylo nutno využít cloudové softwarové nástroje, které jsou však v případě software atlas.ti doposud ve fázi vývoje a jejich využití nelze prozatím doporučit.
Poznámky
1. Takovéto umělé vytvoření kandidáta na kategorii může výzkumníkovi připadat jako nesprávné. Pokud je však daný kandidát na kategorii obecným označením jevů, které jsou kódovány pomocí jemu podřízených kódů, je v datech také přirozeně obsažen.
2. Je možné, že některé málo významné kódy se nehodí do žádné skupiny. Tyto kódy je možno dočasně umístit do skupiny Ostatní.
3. Tento nadřazený kandidát na kategorii může být obsažen mezi stávajícími kandidáty na kategorie, avšak pravděpodobněji bude vytvořen uměle zobecněním několika významově blízkých kandidátů na kategorie.
4. Námi uváděná kostra v Ukázce 9 a schéma na Obrázku 4 prošly mnoha revizemi a nelze očekávat, že by takovéto výstupy byl výzkumník schopen vytvořit napoprvé bez dodatečných oprav a úprav.
Literatura
[1] Birks, M. - Mills, J. Grounded theory: a practical guide. London: SAGE Publications, 2011. ISBN 978-1848609938.
[2] Corbin, J. - Strauss, A. Basics of qualitative research: Techniques and procedures for developing grounded theory. 3rd ed. Thousand Oaks, CA: SAGE Publications, 2008. ISBN 978-1412906449.
[3] Denzin, N. - Lincoln, Y. The SAGE handbook of qualitative research. 3rd ed. Thousand Oaks, CA: SAGE Publications, 2005. ISBN 0-7619-2757-3.
[4] Dobiáš, V. Digitální gramotnost sociálně vyloučených adolescentů. [online], [Citováno 2019-06-20] České Budějovice. Disertační práce. Pedagogická fakulta Jihočeské univerzity v Českých Budějovicích, 2019. Dostupné na www: <https://theses.cz/id/soa1x6/30334209>.
[5] Friese, S. Qualitative data analysis with ATLAS.ti. London: SAGE Publications, 2012. ISBN 978-085702131.
[6] Glaser, B. Theoretical sensitivity: advances in the methodology of grounded theory. Mill Valley, CA: Sociology Press, 1978. ISBN 978-1884156014.
[7] Glaser, B. The grounded theory perspective III: theoretical coding. Mill Valley: Sociology press, 2005. ISBN 978-1884156199.
[8] Glaser, B. - Strauss, A. The discovery of grounded theory: strategies for qualitative research. Chicago: Aldine Publishing, 1967. ISBN 0-202-30260-1.
[9] Guba, E. - Lincoln, Y. Fourth generation evaluation. Thousand Oaks, CA: SAGE Publications, 1989. ISBN 978-0803932357.
[10] Hall, H. - Griffiths, D. - McKenna, L. From Darwin to constructivism: the evolution of grounded theory. Nurse Researcher. [online], [Citováno 2019-05-20] 2013, 20, 3. S. 17-21. Dostupné na www: <https://doi.org/10.7748/nr2013.01.20.3.17.c9492>.
[11] Hendl, J. Kvalitativní výzkum: základní metody a aplikace. Praha: Portál, 2005. ISBN 978-80-7367-485-4.
[12] Charmaz, K. Constructing grounded theory. 2nd ed. London: SAGE Publications, 2014. ISBN 978-0857029140.
[13] Johnson, T. L. Doing Quantitative Grounded Theory: A review. Grounded theory review: An international journal. [online], [Citováno 2019-05-20] 2008, 7, 3. Dostupné na www: <http://groundedtheoryreview.com/2008/11/29/doing-quantitative-grounded-theory-a-review/>.
[14] Kelle, U. "Emergence" vs. "Forcing" of Empirical Data? A Crucial Problem of "Groun-ded Theory" Reconsidered. Forum: Qualitative Social Research. [online], [Citováno 2019-05-20] 2005, 6, 2. Dostupné na www: <http://www.qualitative-research.net/index.php/fqs/article/view/467/1000>.
[15] Mills, J. - Bonner, A. - Francis, K. The Development of Constructivist Grounded Theory. International Journal of Qualitative Methods. [online], [Citováno 2019-05-20] 2006, 5, 1. S. 25-35. Dostupné na www: <https://doi.org/10.1177%2F160940690600500103>.
[16] Miovský, M. Kvalitativní přístup a metody v psychologickém výzkumu. Praha: Grada, 2006. ISBN 978-8024713624.
[17] Oktay, J. Grounded theory. New York: Oxford University Press, 2012. ISBN 978-0199753697.
[18] Ralph, N. - Birks, M. - Chapman, Y. The Methodological Dynamism of Grounded Theory. International Journal of Qualitative Methods. [online], [Citováno 2019-05-20] 2015, 14, 4. S. 1-6. Dostupné na www: <https://doi.org/10.1177/1609406915611576>.
[19] Řiháček, T. - Čermák, I. - Hytych, R. et al. Kvalitativní analýza textů: čtyři přístupy. [online], [Citováno 2019-05-20] Brno: Masarykova univerzita, 2013. ISBN 978-80-210-6382-2. Dostupné na www: <http://www.opvk.fss.muni.cz/ikapsy/uploads/Kvalitativni-analyza-textu.pdf>.
[20] Saldaňa, J. The coding manual for qualitative researchers. 2nd ed. Los Angeles: SAGE Publications, 2013. ISBN 978-1446247372.
[21] Strauss, A. - Corbin, J. Basics of qualitative research: Grounded theory procedures and techniques. Thousand Oaks, CA: SAGE Publications, 1990. ISBN 978-0803932517.
[22] Strauss, A. - Corbin, J. Basics of qualitative research: Techniques and procedures for developing grounded theory. 2nd ed. Thousand Oaks, CA: SAGE Publications, 1998. ISBN 978-0803959408.
[23] Šeďová, K. Zakotvená teorie. In Švaříček, R. - K. Šeďová et al. Kvalitativní výzkum v pedagogických vědách. Praha: Portál, 2007a. 84–96 s. ISBN 978-80-7367-313-0.
[24] Šeďová, K. Analýza kvalitativních dat. In Švaříček, R. - K. Šeďová et al. Kvalitativní výzkum v pedagogických vědách. Praha: Portál, 2007b. 207–247 s. ISBN 978-80-7367-313-.
[25] Švaříček, R. Kritéria kvality kvalitativního výzkumu. In Švaříček, R. - K. Šeďová et al. Kvalitativní výzkum v pedagogických vědách. Praha: Portál, 2007a. 28–50 s. ISBN 978-80-7367-313-0.
[26] Švaříček, R. Hloubkový rozhovor. In Švaříček, R. - K. Šeďová et al. Kvalitativní výzkum v pedagogických vědách. Praha: Portál, 2007b. 159–184 s. ISBN 978-80-7367-313-0.
[27] Urquhart, C. Grounded theory for qualitative research: a practical guide. Los Angeles: SAGE Publications, 2013.. ISBN 978-1847870544.
Zpět na obsah / Back to content